10
Search Engines
There are two basic ways we access information on the Web: browsing and searching. The Web's popularity and power is based on its vast amounts of hyperlinked documents. You can browse from one page to another, clicking on the links which interest you or focus on what you are looking for. Starting from a single home page, or a page such as Yahoo!, you can click to anywhere else on the Web.
However, as more and more information becomes available on the Web, even the best indexes can't provide links to all of the information. With tens of millions of Web pages currently on servers all over the world, it is simply impossible and impractical to "browse" through an index of these documents to find the information you are looking for.
So, as the Web has expanded, we have seen the birth of search engines. At first, these search engines could be found on the more prominent index sites such as Yahoo!. The search engine could locate a list of Web sites that matched a given search criteria. Today Web sites such as Digital Equipment Corporation's AltaVista allow searching of the entire Web with giant supercomputers with gigabytes of memory.
When implementing a search engine on your site, consider how it is implemented from a user's standpoint. Many of the search functions I find on the Web today are totally useless because of the way their interface was designed. The typical user does not want to take the time to learn the syntax of a complicated "valid" search query and is easily annoyed with the "black box" nature of some search mechanisms. This is especially true if the search mechanism fails to return the appropriate (or any) response to the user.
In this chapter, I will introduce you to how Perl5 can be used to access information locally on your site and globally on any site on the Web. If implemented properly, these tools will allow even the most terribly constructed, even misspelled, search query to return appropriate information to those searching your site.
Glimpse is a powerful set of UNIX tools that provide an excellent foundation for a search engine on any UNIX based Web server. Glimpse (GLobal IMPlicit SEarch) is a powerful "indexing and query system" that allows you to search through large numbers of files on your server very quickly. Glimpse is used in the same way as the popular UNIX command grep, except that it can search entire filesystems. For example, if you are looking for the word "help" in some file located anywhere on your server, all you have to do is type "glimpse help," and all lines containing "help" will appear preceded by the file name.
Glimpse was developed by Udi Manber and Burra Gopal, at the University of Arizona, and Sun Wu, at the National Chung-Cheng University in Taiwan. At the time of this writing, Glimpse is at version 4.0. Source and precompiled binaries of Glimpse can be found at
http://glimpse.cs.arizona.edu/
The Glimpse package contains the programs agrep, glimpse, glimpseindex, and glimpseserver. To use Glimpse from the command line you must first "index" your files with glimpseindex. The glimpseindex program creates an optimized index file which contains a "hash" of all the data in your files. Glimpse will search through the index file instead of the actual data. Since Glimpse searches the index file, and not the actual data, it is important that the index file be kept up to date. Running glimpseindex on a nightly basis from cron, a utility which executes tasks on a regular basis, is typically a good idea. Using glimpseindex to create an index is very simple. To use glimpseindex to index all files in the a directory tree rooted at /public_html type (or place in your crontab) the following:
glimpseindex /public_html
Afterwards, Glimpse can quickly and efficiently search through all of the documents indexed in the /public_html directory.
Pay close attention to what you are indexing. If you want to index all of the Web pages on your server, your glimpseindex need only contain the files under the public HTML directory. Images are located in the public HTML document area and need not be indexed, so they should be placed in a directory not indexed by Glimpse.
Glimpse indexes are highly optimized files containing representations of the actual data on your system. By searching for patterns in these index files, Glimpse can quickly query large amounts of data. Glimpse supports three types of indexes: a tiny one (2 to 3 percent of the size of all files indexed), a small one (7 to 9 percent), and a medium one (20 to 30 percent). The relative size of the index file generated can be specified when you build the index file with glimpseindex. The larger the index the faster the search. The size of the index you plan to use should be based on the resources you have on your server. If you had a fast server (say a Silicon Graphics WebForce server) with limited disk resources you would probably want to use a smaller index file. If you have lots of disk space, and a slower Intel-based server, you might consider using a bigger index. Glimpse supports "approximate matching" (finding misspelled words), Boolean queries, and limited forms of regular expressions. Details can be found in the Glimpse man pages or on its Web site.
Now you are probably asking how all of this talk about Glimpse relates to Perl. GlimpseHTTP is a collection of Perl scripts which takes advantage of the power of Glimpse from within Perl. GlimpseHTTP outputs search results in nicely formatted HTML based on a template page (ghtemplate.html) which is easily modified to customize your output.
GlimpseHTTP was written by Michael Smith, Udi Manber, and Paul Klark. As of this writing, the most current version is 2.0 and is available from:
ftp://ftp.cs.arizona.edu/glimpse/glimpseHTTP.2.0.src.tar.Z
Installation of GlimpseHTTP is very straightforward. A step-by-step installation
guide can be
found at:
http://glimpse.cs.arizona.edu/ghttp/install.html
After GlimpseHTTP is installed, the first thing you need to do is make an "archive"
using the included makegharc command. Like Glimpse, GlimpseHTTP requires a few additional
files to be created to function properly. The makegharc program creates some configuration
files, along with the ghindex.html files which contain the search forms. When makegharc
is run, it will prompt you for the location of the archive. As we discussed earlier,
the location needs to be at the root of the public_html tree on your server, and
should not contain images or any other files you do not intend to have publicly available.
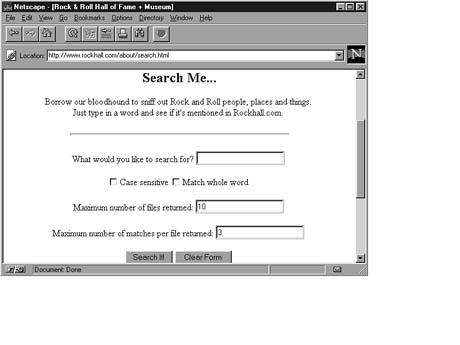
Figure 10.1. GlimpseHTTP in action.
To search using GlimpseHTTP, view the ghindex.html file that has been generated in
each directory. The ghindex.html page has a search form which you can use search
that particular subdirectory of the archive.
GlimpseHTTP allows you to integrate search with browsing. If you have several nested directories which the user may browse, you can include the Glimpse interface in each document such that only the relevant directories will be included in the search. More details are given below.
The current version of GlimpseHTTP was tested under httpd 1.2 HTML server from NCSA, and works on Apache and other Web servers.
Some features of GlimpseHTTP include:
Uses a very small index (3 to 5 percent of the total text) Very fast search Searches for approximate match, allowing errors
For searching outside of your site, a set of modules called WWW::Search has been written by John Heidemann. WWW::Search is a collection of Perl modules which provides a common API to most popular WWW search engines. As of this writing, there are modules which support AltaVista, Yahoo!, Lycos, Hotbot, and WebCrawler. The author is currently developing more modules for other search engines and more sophisticated clients and examples. The latest version of the WWW::Search module can be found at:
http://www.isi.edu/lsam/tools/WWW_SEARCH/
Installation of the module requires Perl5 version 5.003, and is very straightforward. Using the module to generate custom queries to a search engine is very simple.
First, the type of search engine must be defined. Check the documentation to see if the search engine you wish to query is supported, then create a new search:
$search = new WWW::Search(`SearchEngineName');
An example would be:
$search = new WWW::Search(`AltaVista');
Then specify the query string. This string is made up of some specific name value pairs, and is URI encoded.
$search->native_query(`search-engine-specific+query+string');
Here's a documented example which performs an AltaVista search, then prints the URIs resulting from the search. Note that you could easily add nice custom formatting of the results in the while loop.
my($search) = new WWW::Search::AltaVista;
$search->native_query(WWW::Search::escape_query($query));
my($result);
while ($result = $search->next_result()) {
print $result->url, "\n";
};
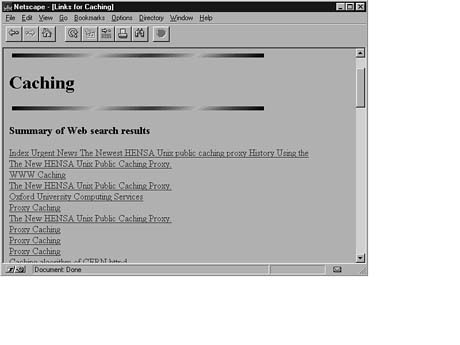
Listing 10.1 is code from search.PL, a small example included with the WWW::Search distribution. This example illustrates the usage of the Search Library. Figure 10.2 depicts an example of output that could easily be generated by search.PL.
# Copyright (c) 1996 University of Southern California.
# All rights reserved.
use strict;
&usage if ($#ARGV == -1);
&usage if ($#ARGV >= 0 && $ARGV[0] eq `-?');
use WWW::Search;
use Getopt::Long;
my(%opts);
&GetOptions(\%opts, qw(v a e=s o=s@)); # i.e -v -e=<string> -o=<options>
&usage if ($#ARGV == -1); # we MUST have one left, the query
my($verbose) = $opts{`v'};
my($all) = $opts{`a'};
&main(join(" ", @ARGV));
exit 0;
sub print_result {
my($result, $count) = @_;
my($prefix) = "";
$prefix = "[$count] " if defined($verbose);
if ($all) {
foreach ($result->urls()) {
print "$prefix$_\n";
$prefix = " ";
};
} else {
print $prefix, $result->url, "\n";
};
}
sub main {
my($query) = @_;
my($count) = "001" if defined($verbose);
my($search) = new WWW::Search($opts{e});
my($query_options_ref);
if (defined($opts{`o'})) {
$query_options_ref = {};
foreach (@{$opts{`o'}}) {
my($key, $value) = m/^([^=]+)=(.*)$/;
$query_options_ref->{$key} = WWW::Search::escape_query($value);
};
};
$search->native_query(WWW::Search::escape_query($query), $query_options_ref);
my($way) = 0; # 0=piecemeal, 1=all at once
my($result);
if ($way) { # return all at once.
foreach $result ($search->results()) {
print_result($result, $count++);
};
} else { # return page by page
while ($result = $search->next_result()) {
print_result($result, $count++);
};
};
};
Figure 10.2. Output possible from search.PL.
Adding a search engine to your site with Glimpse greatly increases the usefulness
and functionality of your service. Whether you have an online catalog or are just
providing information, Glimpse is an easy way to make your information more accessible.
The WWW::Search module is a good way to provide a seamless link from your on-site
search to information resources elsewhere on the Internet.
![]()
![]()
![]()
{kind=link}
{kind=link}